A Fleet of Agents With No Control Plane.
Running a farm of local LLM workers across multiple Macs sounds straightforward until you try it. Each machine produces its own logs, its own tmux session, its own swap pressure.
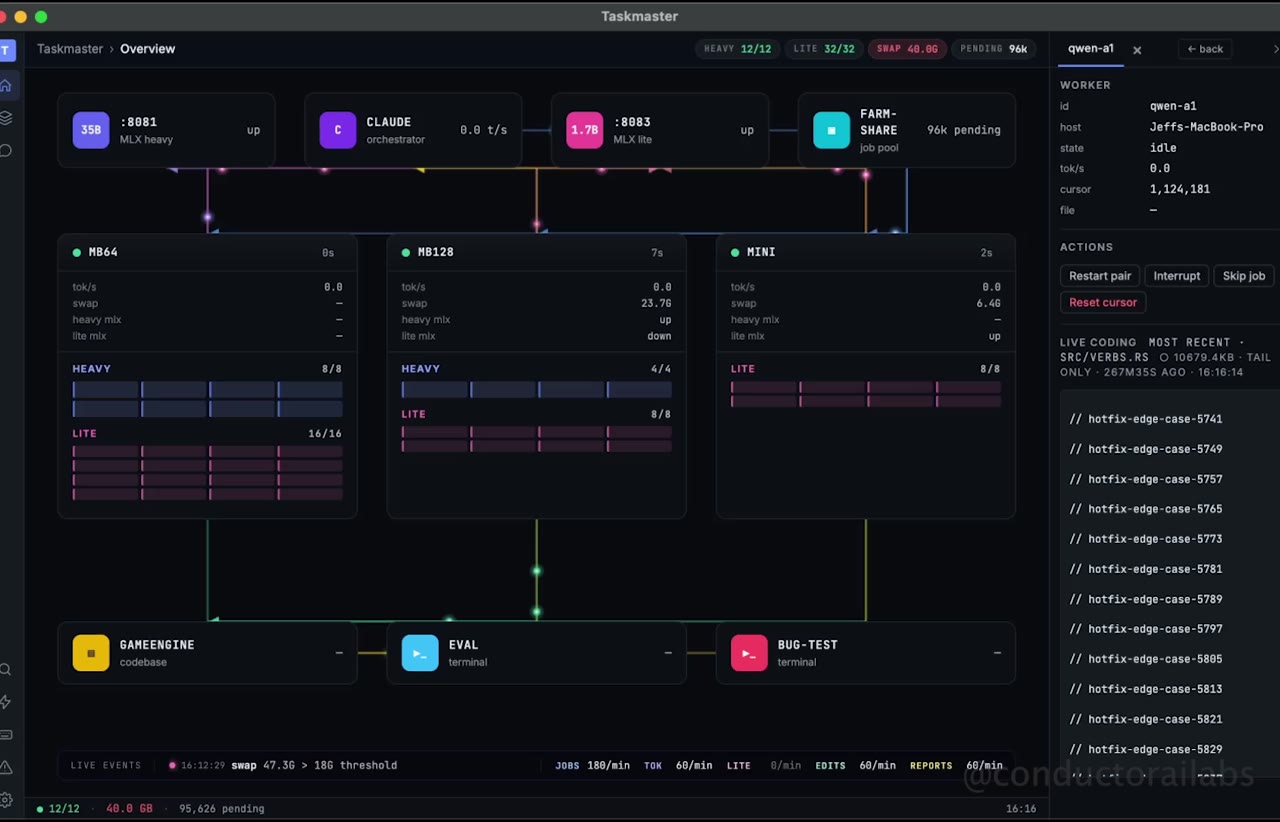
When a worker silently parks for two hours, where do you look?
A qwen-code TUI sitting at an input prompt. A lite runner skipping 20,000 blocklisted jobs in a row. One machine OOMing because of a runaway feeder. There's no single place to see any of it.
Taskmaster is that single place. An Electron desktop app that aggregates real-time state from every machine in the farm via a shared mount point, visualizes the data flow as an animated topology, surfaces problems before they cascade, and lets you act without leaving the dashboard.
The reference deployment runs on three Macs: a 64 GB MacBook Pro hosting the dashboard, a 128 GB MacBook Pro running four heavy qwen workers and eight lite runners, and a Mac Mini running eight lite runners. The architecture scales to one machine or twenty.
The only requirement is a shared mount point. Add a fourth machine, mount the share, drop in a publisher — it appears in the dashboard the next tick. Zero config.